A serverless meme maker: Memendous
Adding text to an image… how hard could it be? Turns out not that hard, but still quite complicated. Here‘s the story behind Memendous.com.
Concepts used:
AWS Lambda/API Gateway/S3
A custom Lambda Layer
Serverless Framework
Python 3.x with Pillow (for the backend Lambda)
Vanilla JS/HTML for the front end
AWS Amplify for hosting
I‘ve been looking for more serverless projects to get under my belt, and a meme maker sounds like a nice limited scope for playing around. Read a few query parameters, feed it into ImageMagick, and slap a bit of HTML around it. I wanted to use Javascript both on the front-end and on the backend (AWS Lambda), and a quick Internet search showed me that Nodejs Lambdas come with ImageMagick built-in. Perfect!
Except it‘s not and it isn‘t. ImageMagick USED to ship with Amazon Linux until there was a security flaw discovered. Now you have to package it yourself. There are Lambda Layers out there that package this software, but in an incomplete fashion. After an hour or two, I decided to scrap the Javascript Lambda function and see what other language ecosystems had to offer.
Lambda also supports Python, and Python has a package called Pillow. Pillow is an imaging library and does exactly what I need. I did still run into the same problem as JS and ImageMagick where it‘s not shipped by default, so I resigned myself to learning about Lambda Layers. Turns out, not that hard. Check that article for more information.
This is not a tutorial on how to build a meme maker on AWS Lambda, this is a collection of my thoughts and thought processes while I was building it.
Where I Started
The first thing I wanted to do was read an image from an S3 bucket and return that image from a Lambda function. No processing, no memes, just read and respond. Turns out, not that easy. Converting the image to a binary took more time thinking than I wanted to spend. After 30 minutes of searching I decided there must be a better way. Let‘s save the image to an S3 bucket using boto3 (built into Python Lambda functions) and return the link. Smart move. Also for the sake of getting this done quickly, I ditched the idea of reading the image from an S3 bucket and just shipped the image inside the Lambda. Not ideal, but good enough for an MVP.
I also wanted to be able to select multiple images and pick from different meme templates. But after spending the day working on the rest, I realized this too was not a necessity for an MVP of a tech demo. I hard-coded one image and moved on.
Where I Ended Up
Well here‘s the entirety of the code for the MVP/tech demo:
# From the Lambda layer
from PIL import Image
from PIL import ImageFont
from PIL import ImageDraw
# AWS imports
import boto3
from boto3 import client
# Python standard library imports
import os
import io
import uuid
import base64
import json
def meme(event, context):
top_text = json.dumps(event['queryStringParameters']['top']).strip('\"')
bottom_text = json.dumps(event['queryStringParameters']['bottom']).strip('\"')
base_path = os.environ['IMAGES_DIR']
base_img = f'{base_path}markmeme.png'
base = Image.open(base_img).convert('RGBA')
# make a blank image for the text, initialized to transparent text color
txt = Image.new('RGBA', base.size, (255,255,255,0))
fnt = ImageFont.truetype(f'{base_path}font/Roboto-Bold.ttf', size=45)
d = ImageDraw.Draw(txt)
d.text((200,10), top_text, font=fnt, fill=(255,255,255,255))
d.text((200,500), bottom_text, font=fnt, fill=(255,255,255,255))
out = Image.alpha_composite(base, txt)
# Generate a UUID for the name
meme_name = uuid.uuid4()
out.save(f'/tmp/{meme_name}.png')
s3_client = boto3.client('s3')
try:
response = s3_client.upload_file(f'/tmp/{meme_name}.png', 'memendous', f'{meme_name}.png')
except:
print("error")
return False
return {
'statusCode': 200,
'headers': {
'Access-Control-Allow-Headers': 'Content-Type',
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'OPTIONS,POST,GET'
},
'body': json.dumps(f'https://insert-s3-link-here/{meme_name}.png')
}I start with fairly standard imports, (with the Pillow stuff imported from a Lambda Layer I created). I then read the query params from the URL for top and bottom text.
The image I‘m using is stored in /images, which is saved in an environment variable inside the serverless.yml file (brought to you by the great Serverless Framework). I then open the image (markmeme.png) and use Pillow to convert it to RGBA (so I can have a transparency layer to drop the text on).
Inside the image directory I also included and hard-coded a font. I wanted Arial like most memes use, but Google Fonts doesn‘t have Arial so I went with Roboto. I downloaded Roboto.ttf from Google Fonts and ship it right inside the Lambda. Best practice? Probably not. But it works. I‘m also hard-coding the font size and location, which really limits how much text I can write without it going off the edge of the screen. But again, tech demo. Fixing that wasn‘t necessary for v1.
I pretty quickly ran into file name conflicts inside S3, so I brought in the UUID package to make sure the filenames are unique. I then save the image to the local disk (/tmp) and then use AWS‘s included boto3 library to ship it to S3, then return a status of 200 and a link to the image. The back end is done!
(side note, I turned off CORS by accepting all origins because I code in AWS Cloud9 which CORS does not like when you‘re also hosting at AWS… there‘s probably a better way but eh)
To Display It All
To build a front-end, I just slapped some vanilla Javascript/AJAX and HTML together. A couple of input boxes for top and bottom text, an XHR request to the API Gateway, and show the meme below that.
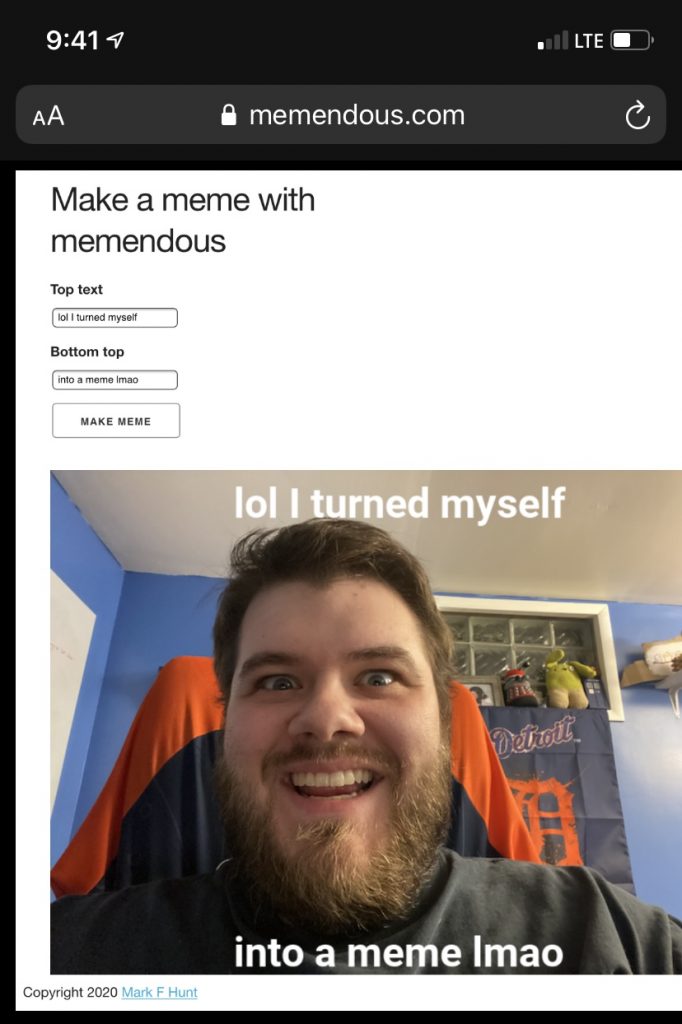
Wrapping Up
This is a silly little project that means nothing. It‘s perfect for learning. And it‘s perfect for Lambda. If I was paying $5/mo to host this at DigitalOcean I‘d be crazy, because no one is gonna use it. But at Lambda, if no one uses it I don‘t pay anything.
If you‘re a solo developer working on small little hobby projects like this one, I highly recommend serverless technologies like AWS Lambda and DynamoDB (or their equivalents at Azure). Cost savings aside, it saves operational overhead as well (not having to admin/patch/configure servers). Bear in mind it does trade that for the overhead of making sure you‘re fitting inside of the vendor‘s preferred workflow.